It would be an understatement to say that HTTP Caching is a more feared part of the web platform. Decades of legacy, confusing names and implementation differences make caching a nightmare to understand. Given the fear of permanently caching a broken asset in user's browsers, it's no wonder that sometimes you'll be tempted to ignore caching all together.
"Sure, users will download things a couple extra times if I don't add Cache-Control, but at least I won't muck something up."
Recently, I learnt this attitude is dangerously incorrect.
If you don't set a Cache-Control header, browsers might cache your response by default and use the cache without revalidating with your server. This causes exactly that situation we all fear - old assets getting stuck in the user's browser.
Background
There's 3 ways a browser fulfills a HTTP request:
- Sending the request to the server.
- Returning the cached data, without touching the server.
- Sending the request to the server, but including the
EtagorIf-Modified-Sinceheaders. This is known as revalidating the cached data. The server can either send a new response or confirm the browser's cache is up to date (304 Not Modified) and skip sending the response body.
The first time a URL is requested, it always used the first mode. But as developers, we can control headers like Cache-Control, Last-Modified and Expires in our server's response, which affects the mode the browser will use next time.
In a production environment, it may be more complex as there may be more software (CDNs, proxies) in between our server & the browser. CDNs might have their own caches or change what we send to the user.
S3's Default Settings are Dangerous with Browsers
So how does this work with a real web server? Say your application is loading assets (i.e. making fetch requests) directly from a public S3 bucket. With the default configuration, if you request the same URL twice it'll be served directly from the browser's cache the 2nd time - no revalidation:
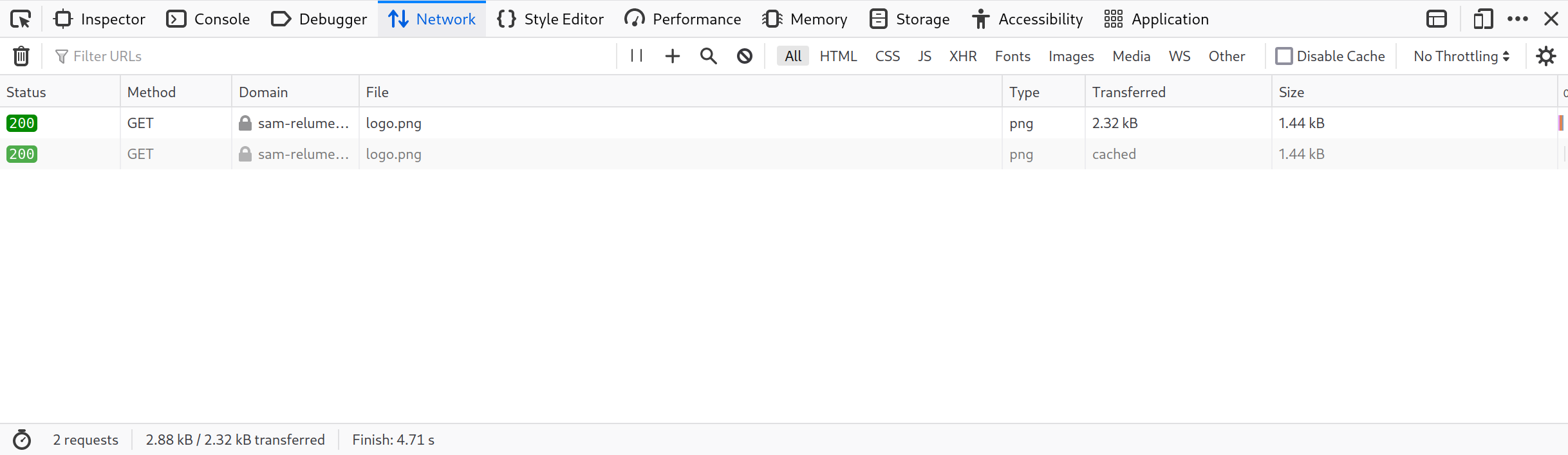
WTF! This means if I updated logo.png on the server, people who've seen the old logo wouldn't see the new one.
Digging into this, I wouldn't blame you for being surprised. S3's response looks something like this:
HTTP/1.1 200 OK
Accept-Ranges: bytes
Content-Length: 1440
Content-Type: image/png
Date: Fri, 15 Sep 2023 04:54:54 GMT
ETag: "3fcf456b3eef7e142c53672fdae3c2c4"
Last-Modified: Mon, 13 Mar 2023 04:45:18 GMT
Server: AmazonS3
Intuitively, I'd expect that the browser doesn't cache this response as there is no Cache-Control header. I was totally wrong.
No Cache-Control but got a Last-Modified?
The HTTP Caching RFC says browsers are allowed to calculate so called "heuristic freshness":
4.2.2. Calculating Heuristic FreshnessSince origin servers do not always provide explicit expiration times, a cache MAY assign a heuristic expiration time when an explicit time is not specified, employing algorithms that use other header field values (such as the Last-Modified time) to estimate a plausible expiration time. This specification does not provide specific algorithms, but does impose worst-case constraints on their results.
In plain English, this means if there's no Cache-Control or Expires header, the browser can invent one.
And in reality, browsers aggressively invent one.
Chrome takes 10% of the time between Date (now) and Last-Modified. S3 includes a Last-Modified header; the time the object was updated. So if you uploaded the object a while ago, Chrome users are going to cache it for 10% of that time without revalidating. 10% of a while might still be a very long time.
Safari does the same, owing to its shared heritage. Firefox is similar, but thankfully it applies a maximum of 1 week (so things won't be as out of date for Firefox users).
TL;DR: S3's default causes browsers to cache objects without revalidation for an unbounded (except in firefox) amount of time.
How bad is S3's default?
One saving grace is that browser's have different caching behaviour for the main HTML of the page. It's easy for a user (to be instructed) to hit Ctrl+R which will cause the browser to refresh that HTML at least. If you've run into this pitfall with assets, you can update the HTML to reference new object paths.
But if you're fetching S3 objects using the fetch api, creating img tags or something more exotic, you'll need to watch out for this pitfall.
How do you fix S3 here?
Broadly, you can either:
- Change the URL every time you fetch or update the content. E.g. add
?v=<time>as a query string. - Configure S3 (or a proxy in front of it) to add a
Cache-Controlheader. You could add a short max age (e.g.Cache-Control: maxage=60) to allow a small window of no-revalidation usage, or force the browser to always revalidate (Cache-Control: no-cache).
Even if you set short Cache-Control headers, the browser is still allowed to store the cached resource as long as it sees fit. That means users will still save bandwidth if their cache is up-to-date (304 Not Modified), even though it doesn't help latency. If you don't want the browser to ever cache anything, that's Cache-Control: no-store.
Conclusion
Always set a Cache-Control on HTTP responses. Omitting that header will lead to browsers caching your response & using it without revalidation, which is likely undesired.
I hope you enjoyed this article. Contact me if you have any thoughts or questions.
© 2015—2025 Sam Parkinson